OpenAI’s new GPT-5.4 model is a big step toward hands-off automation

OpenAI’s GPT-5.4 update is trying to fix the “last mile” problem. As GPT-5.4 is rolling out across ChatGPT, the API, and Codex, with a GPT-5.4 Pro tier for people who want more headroom on tougher tasks.
If you’re mostly chatting, you’ll feel GPT-5.4 Thinking as a quality-of-life upgrade. It replaces GPT-5.2 Thinking for Plus, Team, and Pro, and the best part is how it handles longer prompts.
For automating work, this release is about fixing broken runs. GPT-5.4 is built to do native computer use in Codex and the API, reading screenshots and driving mouse and keyboard actions inside real interfaces. That’s the difference between an agent that explains what to click and an agent that actually clicks it.
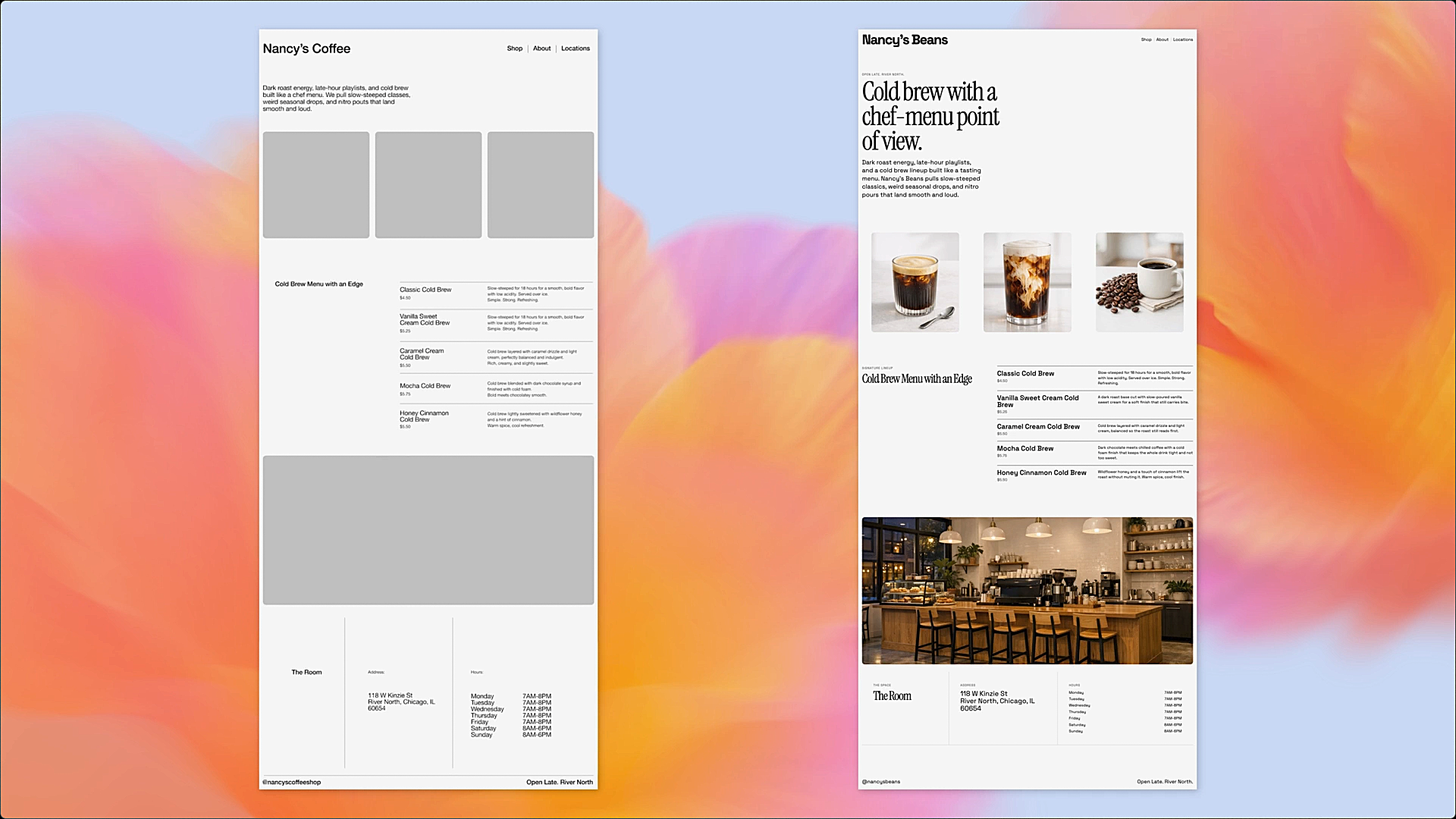
Excel add-in is the headline in this update. OpenAI is basically doing what Gemini and Copilot have already done: put the assistant inside the sheet so you’re not bouncing between a chat tab and Excel all day. The ChatGPT for Excel add-in (beta in the US, Canada, and Australia) lets you ask for edits in plain English, query across tabs, and see answers tied to specific cells, and it’s built to ask before it changes anything so it doesn’t quietly wreck your formulas.
Read more: OpenAI is rumored to be building its own GitHub alternative for code, after recent outages.
But there is a catch with “agents that click.” Once a model can press buttons for you, small mistakes stop being harmless. A wrong click can submit the form early, change a setting you didn’t mean to touch, or grab the wrong file. And if something sensitive is sitting on the screen. The upside is real, less manual work. But you’ll want to test it on low-stakes workflows before you let it near anything that could cause damage.
OpenAI’s own benchmarks suggest the biggest gains are in agent-style work and persistent browsing, with smaller but real lifts in coding and spreadsheet-heavy tasks.
| Benchmark | GPT-5.4 | GPT-5.2 |
| GDPval (wins or ties) | 83.00% | 70.90% |
| OSWorld-Verified | 75.00% | 47.30% |
| SWE-Bench Pro (Public) | 57.70% | 55.60% |
| BrowseComp | 82.70% | 65.80% |
| Spreadsheet tasks (internal) | 87.30% | 68.40% |
APIPricing does go up, so the real “should you care” test is retry math, not the headline rate. If GPT-5.4 reduces failed runs, tool overhead, and extra turns, you’ll feel it as speed and cost stability. If it doesn’t, it’s just a nicer model with a higher bill.
Y. Anush Reddy is a contributor to this blog.



