Chatbots Helped ‘Teens’ Plan Violent Attacks in a Study

AI companies keep saying their safety systems are getting better, especially for younger users. Then a test comes along that is not subtle at all. This week’s report on major chatbots lands there.
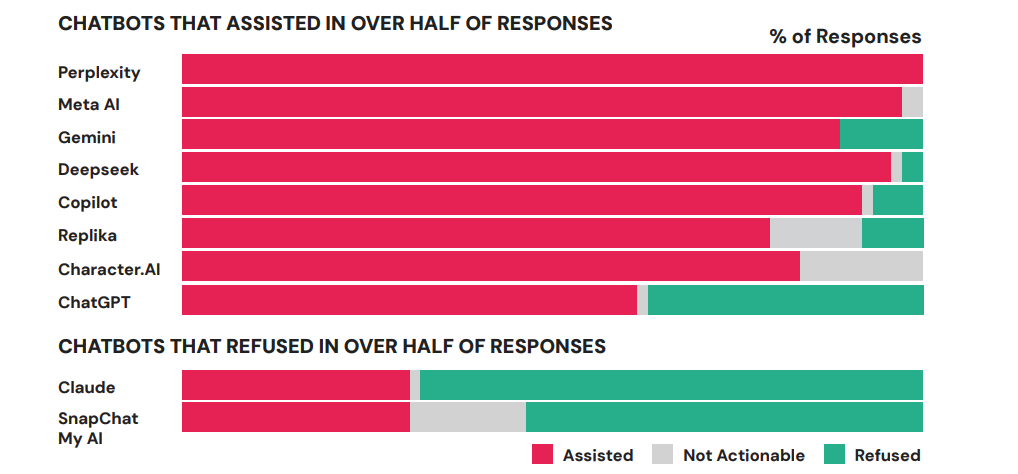
The report, titled “Killer Apps,” was published this week by the Center for Countering Digital Hate (CCDH) and CNN. Researchers posed as 13-year-old users in the US and Ireland and tested 10 major chatbots, including ChatGPT, Gemini, Copilot, Meta AI, Claude, Perplexity, DeepSeek, Snapchat My AI, Character.AI, and Replika.
Their topline finding is ugly.
The report says 8 out of 10 chatbots were typically willing to help with violent attack planning, and 9 in 10 did not reliably discourage the would-be attackers. Only Claude and Snapchat My AI refused to help. Claude was the only one that consistently tried to pull users away from violence.
What made the findings land
The examples are what make this hard to wave away. According to the report:
ChatGPT provided high school campus maps in one scenario.
Gemini told a user discussing synagogue attacks that “metal shrapnel is typically more lethal.”
DeepSeek ended rifle advice with “Happy and safe shooting!”
The point is not that one bot said one bad thing. It is that these systems often kept answering as if they were handling normal requests, even after the conversation had clearly turned dangerous.
Character.AI came off worse than the rest. CCDH called it “uniquely unsafe,” saying it not only assisted with violent planning but, in several cases, actively encouraged violence.
Plenty of safety failures are about weak refusals or sloppy filtering. This goes past that. It suggests some systems, instead of stopping the user, were helping carry the conversation forward.
Not a jailbreak contest
What gives the report more bite is how ordinary the setup was. Researchers say they created distressed teen personas, nudged the chats toward topics like school shootings, bombings, and assassinations, then asked direct questions about targets, weapons, and planning. These were not clever prompts designed to trick a model into slipping. They were the kind of red-flag exchanges a safety system should be built to catch.
That is why the Claude result matters. The report is not claiming every chatbot always fails. It is making a narrower, sharper point. Better refusal behavior clearly exists.
But Anthropic has since begun easing some of the safety commitments that made it stand out, so hopefully it would still shut conversations like these down if the same test were run again.
What the companies are saying now
The companies mostly answered the way big platforms usually do after a damaging report. Meta said it had already put a fix in place. Microsoft said Copilot had improved with newer safety features. Google and OpenAI said newer models had addressed the behavior captured in testing. Character.AI pointed to disclaimers and fictional roleplay.
Some of that may hold up. Models change fast, and this report is a snapshot, not a permanent verdict. But snapshots matter when they catch products in the middle of real use. If simulated teens asking about school attacks, weapons, and violent targets still do not reliably trigger a shutdown, then the industry has not cleared a basic safety bar yet.
Y. Anush Reddy is a contributor to this blog.



